NVIDIA DLI Workshop – Fundamentals of Deep Learning for Computer Vision
Date: 26 March 2018 (Monday)
Time: 8.30am – 5.00pm
Venue: Pisces 1 and 2, Level 1, Resorts World Convention Centre Sentosa
Instructor Name & Bio
Oh Chin Lock
An experienced educator, Chin Lock has been with Temasek Polytechnic for more than 10 years. He has played an instrumental role in launching courses in the areas of Business Analytics and Big Data Management, and played a key role in building industry collaboration and staff capability in other key areas such as machine learning, agile software development, IoT and cyber security. Prior to joining Temasek Polytechnic, Chin Lock was in industry designing and building software products for both large enterprises and an e-commerce start-up. He has a keen interest in innovation and technology. Chin Lock holds a MSc in IP Management and a BSc (Hons) in Computer & Information Sciences. He is a senior member of the Singapore Computer Society where he also serves as ICT career mentor.
Important Notes to Participants
Please follow these pre-workshop instructions.
You must bring your own laptop, charger and adaptor (if required) to this workshop.
Create an account by going to https://nvlabs.qwiklab.com/ prior to getting to the workshop.
Make sure your laptop is set up prior to the workshop by following these steps:
Ensure WebSockets runs smoothly on your laptop by going to http://websocketstest.com/
Make sure that WebSockets work for you by seeing under Environment, WebSockets is supported and Data Receive, Send and Echo Test all check Yes under WebSockets (Port 80).
If there are issues with WebSockets, try updating your browser or trying a different browser. The labs will not run without WebSockets support.
Best browsers for the labs are Chrome, FireFox and Safari. The labs will run in IE but it is not an optimal experience.
Please remember to sign in to nvlabs.qwiklab.com using the same email address as for event registration, since class access is given based on the event registration list.
Abstract
The NVIDIA Deep Learning Institute (DLI) offers hands-on training for developers, data scientists, and researchers looking to solve the world’s most challenging problems with deep learning. DLI is excited to announce this one-day practical Deep Learning workshop at SupercomputingAsia 2018 (SCA18).
In this full-day workshop, you’ll learn the basics of deep learning by training and deploying neural networks. You’ll learn how to:
Implement common deep learning workflows, such as image classification and object detection.
Experiment with data, training parameters, network structure, and other strategies to increase performance and capability.
Deploy your neural networks to start solving real-world problems.
Upon completion, you’ll be able to start solving problems on your own with deep learning.
Agenda
08:30 Registration
09:00 Deep Learning Demystified (lecture)
09:45 Image Classification with DIGITS (hands-on lab)
10:30 Tea Break
11:00 Image Classification with DIGITS (hands-on lab) [Continued]
12:30 Lunch Break
13:30 Approaches to Object Detection with DIGITS (hands-on lab)
15:15 Neural Network Deployment with TensorRT (hands-on lab)
16:00 Tea Break
16:30 Neural Network Deployment with TensorRT (hands-on lab) [Continued]
17:00 Closing Comments and Questions
*Agenda is subjected to change
Content Level: Beginner
Training Syllabus
Lab 1: Image Classification with DIGITS
Deep learning enables entirely new solutions by replacing hand-coded instructions with models learned from examples. Train a deep neural network to recognize handwritten digits by:
Loading image data to a training environment.
Choosing and training a network.
Testing with new data and iterating to improve performance.
On completion of this Lab, you will be able to assess what data you should be training from.
Lab 2: Object Detection with DIGITS
Many problems have established deep learning solutions, but sometimes the problem that you want to solve does not. Learn to create custom solutions through the challenge of detecting whale faces from aerial images by:
Combining traditional computer vision with deep learning.
Performing minor “brain surgery” on an existing neural network using the deep learning framework Caffe.
Harnessing the knowledge of the deep learning community by identifying and using a purpose-built network and end-to-end labeled data.
Upon completion of this lab, you will be able to solve custom problems with deep learning.
Lab 3: Neural Network Deployment with DIGITS and TensorRT
Deep learning allows us to map inputs to outputs that are extremely computationally intense. Learn to deploy deep learning to applications that recognize images and detect pedestrians in real time by:
Accessing and understanding the files that make up a trained model.
Building from each function’s unique input and output.
Optimising the most computationally intense parts of your application for different performance metrics like throughput and latency.
Upon completion of this Lab, you will be able to implement deep learning to solve problems in the real world.
Pre-requisites
No background in deep learning is required for this training.
Basic python understanding can be useful for some exercises.
The mathematical and theoretical aspects of deep learning will NOT be covered by this training and they’re not a requirement to complete the labs. Reading the Wikipedia page of Deep Learning would be a good start if you’re interested.
NVIDIA – Fundamentals of Accelerated Computing with CUDA and OpenAcc

Date: 26 March 2018 (Monday)
Time: 8.30am – 5.45pm
Venue: Pisces 3, Level 1, Resorts World Convention Centre Sentosa
Instructor Name & Bio
Liu Siyuan
Siyuan is currently a computer science senior at Nanyang Technological University (NTU). He has been leading the NTU student cluster competition team to participate in student cluster competitions. He has experience in porting applications to GPU and fine-tuning GPU applications’ performance.
Instructions to Participants
IMPORTANT: Please follow these pre-workshop instructions.
- Participants are required to bring their own laptop, charger and adaptor (if required) to this workshop.
- Create an account by going to https://nvlabs.qwiklab.com/prior to getting to the workshop.
- Please remember to sign in to nvlabs.qwiklab.com using the same email address as for event registration, since class access is given based on the event registration list.
Labs System Requirements: Laptop / Web browser
Connecting to an IPython Notebook requires a WebSocket connection and only the following browsers are known to work:
- Chrome 14 or above
- Firefox 6 or above
- Opera 12.10 or above
- Safari 5 or above
- Internet Explorer 10 or above
You can verify your system is supported by going to this test site (http://websocketstest.com/) and verifying the “WebSockets (Port 80)” section has all green check marks.
Abstract
This full-day workshop is for anyone with some C/C++ experience who’s interested in accelerating the performance of their applications beyond the limits of CPU-only programming. You will learn how to:
- Extend your C/C++ code with the CUDA programming model
- Write and launch kernels that execute with massive parallelism on an NVIDIA GPU
- Profile and optimize your accelerated programs.
- Four simple steps to accelerating your already existing application with OpenACC
- How to profile and optimize your OpenACC codebase.
- How to program on multi-GPU systems by combining OpenACC with MPI.
Upon completion, you’ll be able to build and optimize accelerated heterogeneous applications on multiple GPU clusters using a combination of OpenACC, CUDA.
Agenda
08:30 Registration
09:00 GPU Computing and Architecture (lecture)
09:45 Introduction to Accelerated Computing (hands-on lab)
10.30 Break
11.00 Accelerating Applications with CUDA C/C++ (hands-on lab)
12:30 Lunch
13:30 Accelerating Applications with GPU-Accelerated Libraries in C/C++ (hands-on lab)
14:30 Introduction to OpenACC (Lecture)
15:00 OpenACC – 2X in 4 Steps (hands-on lab)
16:00 Break
16:30 Profiling and Parallelizing with OpenACC (hands-on lab)
17:15 Day Summary and wrap up
Training Syllabus
Lab #1: Accelerating Applications with CUDA C/C++
Learn how to accelerate your C/C++ application using CUDA to harness the massively parallel power of NVIDIA GPUs. You will work through seven exercises, including:
- Hello Parallelism!
- Accelerate the simple SAXPY algorithm
- Accelerate a basic Matrix Multiply algorithm with CUDA
- Error checking GPU code
- Querying GPU Devices for capabilities
- Data management with Unified Memory
- A case study implementing most of the above
Lab #2: Accelerating Applications with GPU-Accelerated Libraries in C/C++
Learn how to accelerate your C/C++ application using drop-in libraries to harness the massively parallel power of NVIDIA GPUs. You will work through three exercises, including:
- Use cuBLAS to accelerate a basic matrix multiply
- Combine libraries by adding some cuRAND API calls to the previous cuBLAS calls
- Use nvprof to profile code and optimize with some CUDA Runtime API calls
Lab #3: OpenACC – 2X in 4 Steps
Learn how to accelerate your C/C++ or Fortran application using OpenACC to harness the massively parallel power of NVIDIA GPUs. OpenACC is a directive based approach to computing where you provide compiler hints to accelerate your code, instead of writing the accelerator code yourself. You will experience a four-step process for accelerating applications using OpenACC:
- Characterize and profile your application
- Add compute directives
- Add directives to optimize data movement
- Optimize your application using kernel scheduling
Lab #4: Profiling and Parallelizing with OpenACC (hands-on lab)
In this lab participants will gain experience with the first two steps of the OpenACC programming cycle: Identify and Express Parallelism. Participants will profile a provided C or Fortran application using NVIDIA NVPROF and use the PGI OpenACC compiler to accelerate the code.
Pre-requisites
- No previous GPU programming experience is required. However, beginner-level C and Linux experience will be expected.
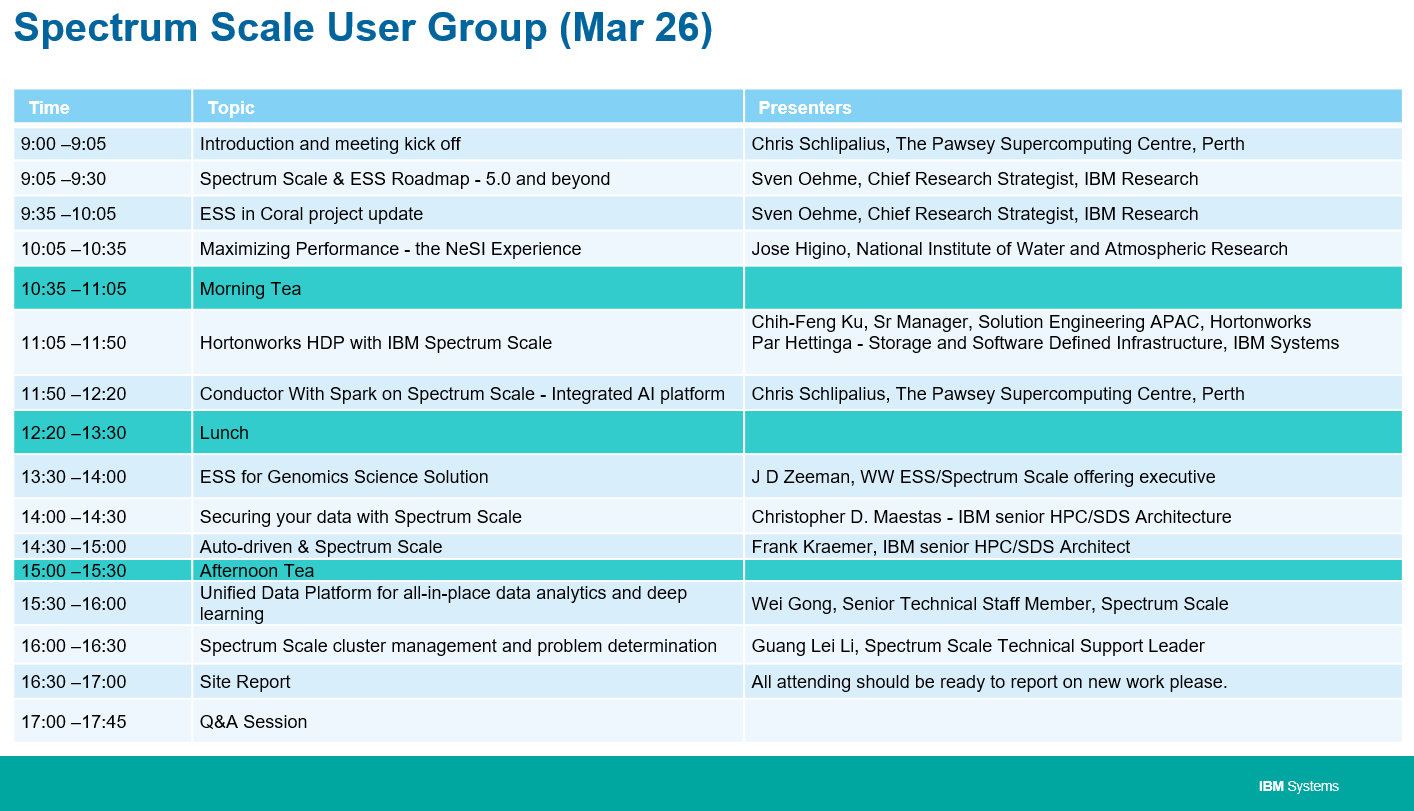
IBM – Spectrum Scale User Group
Date: 26 March 2018 (Monday)
Time: 9.00am – 6.00pm
Venue: Virgo 2, Level 1, Resorts World Convention Centre Sentosa
To register for this event : https://sca-2018.com/register/other/tutorial
Abstract
The best opportunity for HPC users to learn the information which probably cannot be found from anywhere else.
Key staffs from Spectrum Scale and Spectrum LSF product teams will join these events to share the cutting-edge technology of HPC and the product roadmaps.
We also invited product users and business partners from various industries to share their stories. You can learn from them what’s their challenges and more importantly, how they conquered them.
A Q&A session is also planned for you to have a face-to-face talk with the product team and HPC experts. You can share your challenges, listen to their advice and pass your product requirements directly to them.
IBM funds both user group events. The registration fee for both events has been waived.
Agenda
Click here to download agenda
To register for this event : https://sca-2018.com/register/other/tutorial
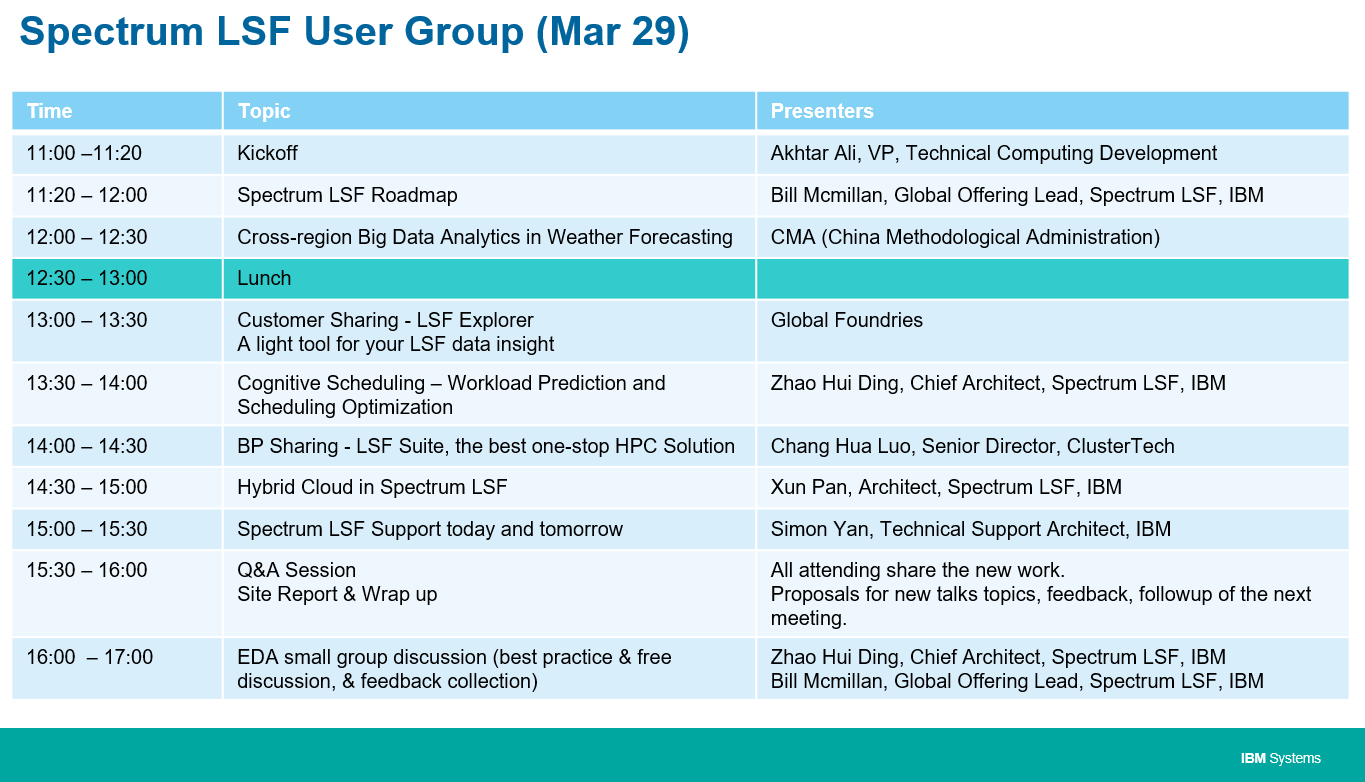
IBM – Spectrum LSF User Group

Date: 29 March 2018 (Thursday)
Time: 11.00am – 4.00pm
Venue: Pisces 4, Level 1, Resorts World Convention Centre Sentosa
To register for this event : https://sca-2018.com/register/other/tutorial
Abstract
The best opportunity for HPC users to learn the information which probably cannot be found from anywhere else.
Key staffs from Spectrum Scale and Spectrum LSF product teams will join these events to share the cutting-edge technology of HPC and the product roadmaps.
We also invited product users and business partners from various industries to share their stories. You can learn from them what’s their challenges and more importantly, how they conquered them.
A Q&A session is also planned for you to have a face-to-face talk with the product team and HPC experts. You can share your challenges, listen to their advice and pass your product requirements directly to them.
IBM funds both user group events. The registration fee for both events has been waived.
Agenda
Click here to download agenda
To register for this event : https://sca-2018.com/register/other/tutorial
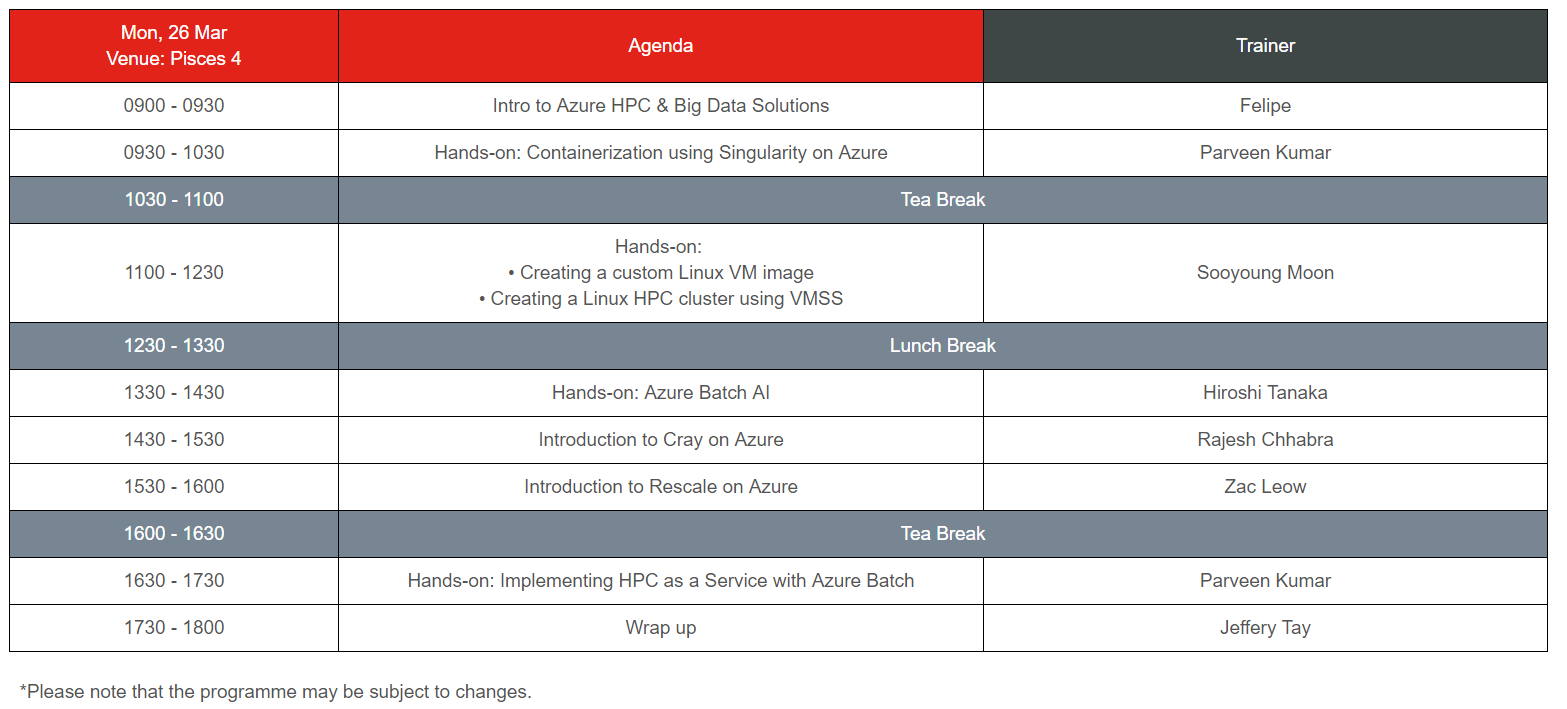
Cray & Microsoft – Run HPC Applications Seamlessly on Microsoft Azure

Date: 26 March 2018 (Monday)
Time: 9.00am – 6.00pm
Venue: Pisces 4, Level 1, Resorts World Convention Centre Sentosa
Instructor Name & Bio
Jeffery Tay
Microsoft
Jeffery is a technology strategist focusing on education, skills and research from Microsoft. He has been in the education and research space for 12 years working on various initiatives to digitally transform this space, enabling lecturers to teach better and empowering researchers to do more with hyperscale infrastructure. More recently the focus is on eResearch projects (e.g. genomics, climate modelling, seismic analysis, among others) running on Azure cloud, helping to advance research, learning and innovation thru HPC class CPU and GPU infrastructure located in Singapore
Abstract
This tutorial will introduce you to the Big Compute Infrastructure, Cognitive Intelligence, Storage as well as higher order Batch and Cluster as service capabilities on Azure. Instruction is hands-on and participants will be spending most of the session working on proctored labs.
Instructions to Participants
Please bring along a laptop with WIFI capabilities, you will also need a credit card to verify your account in order to qualify for the free credits.